At Trello, on the mobile team, we had a formal way of allocating engineering time to either working on PM-led or Engineering-led initiatives.
A PM-led initiative was something that ultimately rolled up to a OKR that was well-understood by the business. The requirements came from the PM and the PM could assess acceptability. An Engineering-led initiative was something like tech debt, changing our dependency package manager, improving CI build times or anything where the requirements came from the team itself and the PM didn’t know or care about it (and neither did anyone outside the team).
So, let’s say we decided the split was 60% on product manager led initiatives and 40% on what we called engineering-led. The split is arbitrary—the EM and PM agreed on what was appropriate for their team and set it for the year.
Then, any individual engineer at any one time (for a couple of sprints) was on either a PM-led project or an Engineering-led project. We did not want a single engineer to be split across PM/Eng-led work. This made it easy to know we were allocating correctly (without having to track time on individual stories or cases).
So, if it was 60/40 and we had 10 engineers, 6 would be on PM-led, and 4 would be on engineering-led at any one time, but it rotated.
This just needed to be mostly right over the course of a year—on any specific month it could be a little off if over the long-term, it matched. For example, If the PM didn’t have work ready, we could do more engineering-led work temporarily.
I believe I just coined a new programming term: if-bomb: adding a bunch of heinous if’s for a special case “Dropped an if-bomb on my code”
To be clear, this is a well-known anti-pattern, covered in Patterns of Enterprise Application Architecture by Martin Fowler. I started calling them “if-bombs” to discourage their use. One remedy is the Special Case pattern, but there are others. A special case of the Special Case pattern is the Null Object pattern, which is used when the special case handles null references.
When I begin a coding session, I start by taking the task I need to do and breaking it down in fine detail. For example I am working on personal productivity system, which has a “Project” concept. In my first pass, Projects just had a name field. I was just working on getting the relations right. Now, I want to flesh it out a bit. I have a Jira issue with the title: Add “color”, “startDate”, and “endDate” fields to Projects.
Here’s how I break that down:
Add fields to DB entity
Add fields to DB createProject, updateProject
Test DB
Add fields to server GQL createProject, updateProject
Add fields to client GQL createProject, updateProject
Add fields to client GQL project query
Add fields to client model and redux initialize
Add fields to redux createProject, updateProject
Add fields to API/Optimistic updateProject, createProject
Test API/optimistic update/redux
Add a color picker for setting color
Add UI to create project dialog
Add UI to update project dialog
Test UI
I could get more granular, but this is about the level I like. I put them in my task manager to keep me on track and to make sure I’ve thought the problem through. This will roughly be the order I do it and the commits I make.
It guides the session and keeps me on track. If I don’t finish, I just move the incomplete tasks to the next day, which lets me preserve some of the momentum from the previous one. Also see: Green, Refactor, Red, where I end the session with a failing test for the next task I want to do.
Chapter 1 of Joel Spolsky’s User Interface Design for Programmers is titled “Controlling Your Environment Makes You Happy” and contains a story of Joel’s time working in a bakery which concludes:
The more you feel that you can control your environment, and that the things you do are actually working, the happier you are.
This is why I Use My First Commit to Fix CRAP. It takes 5-10 minutes and lets me exert some control on my environment. I start each day with a small success. If I feel frustrated later in the day, I just do it again.
I saw a suggestion to use Subject-First Commit Messages to make it easier to scan the log. I switched over to this about two weeks ago and like it.
When you write commit messages this way, they tend to result in passive voice sentences like “Project cleared from project prompt dialog when closed” and “Title added to date prompts”. Many style books suggest that you not use the passive voice, which is then repeated as a rule. But, the passive voice is useful, and is often used by the best writers (go check your favorite). Even those style books (like Strunk and White) give exceptions.
When writing a sentence, it’s important to control the subject. In most commit messages, the implicit subject is the programmer. For example, in “Added title to date prompts”, the subject “I” is dropped. Since we know that the programmer is making the commits, we don’t need to constantly repeat it. It’s better to pick the most important noun in the sentence and make that the subject, and to do that (in English) you have to use the passive voice.
The second discipline in The Four Disciplines of Execution (4DX) is to act on the lead indicators to accomplish a big and important long-term goal. To practice this discipline, pick some short-term thing that you could do at any time. You have to design it so that continuously achieving the lead indicator would eventually build up and achieve the long term goal. For example, I want to publish a book by June 30, but what I track is the number of days I work on it each week—my goal is five per week. Every day, I have a choice to do this. It’s a metric I can move at any time. I think it’s very likely that if I accomplish this goal every week, I will have a book by June 30.
The third discipline helps you stay on track by asking you to build a scoreboard that lets you know if you are winning. I track my lead indicators in my journal and with some software that I am working on. I also decided to use the Chronicling App on my iPhone to make it extra visible as a widget on my home screen. The scoreboards need to be visible enough so that you are constantly reminded of it. The bulk of my day is spent NOT working on the book, but I want to keep it top of mind so that I can put in at least an hour each day.
I would love to apply this to tiny tech debt payments. This is something I try to do almost every day, guided by the Tech Debt Detectors in my Editor. The work ends up in commits that go into the PR I’m working on because they are targeted in the area I am trying to change.
The commit is the leading indicator. Over the course of months, they will result in a cleaner codebase that is easier to work on. Each one contains a refactoring or a new test, but not every refactor or test counts. When I am doing TDD or just testing as I go, that’s not a debt payment. Neither is cleaning up a PR for review or removing a TODO in the grace period. So, I can’t just look for commits that add tests or commit messages with the word “refactor”.
To track these commits, I will use the string “[payment]” in the commit messages. My scoreboard is just:
which would show me the number of commits in the last 10 that were payments. My goal for now is that it not be 0. I run yarn lint and yarn test constantly, so I could just make them report the number.
If you are on a team working on a messy codebase, then adopting something like this gives you agency every day to make some kind of difference. If you do it, then invest the time to make a central scoreboard to make that work visible.
Let’s say you don’t use coverage tools, and you’re looking at a function that you want to change and you wonder if it’s tested.
No problem—just change something random in the function.
Change a less-than to a greater-than, an && to an ||, or slightly alter an arithmetic expression. Change something small that keeps the code syntactically correct, but slightly wrong otherwise. Now, run your tests.
If tests fail, undo that change and try something different.
If the tests pass, you know this line is untested. Add a failing tests to force you to undo your change.
Keep perturbing lines until you feel comfortable that you’ve covered enough of the function to make it less risky to change.
Dates and Integers have a natural ordering. We all agree that January 1st is before January 2nd and ten comes after nine. But, there is no natural ordering for things like vectors, complex numbers, and matrices because they are multi-dimensional. Unfortunately, most things in real life are multi-dimensional.
A common way to deal with ordering a list of things in software is to put their attributes in different columns. You see this in email clients, spreadsheets, and lots of other software. Then, when you click on a column, the list is sorted by that attribute. You can explore various orderings for different contexts. Some might be more useful—for example, in my WordPress backend, I sort my posts by reverse chronological date. But, it’s valid to sort them by title if you need to. Good versions use the previous sort choice as a sub-sort that breaks ties in the main sort.
Another way is to come up with some kind of function of the attributes that results in a single-dimensional attribute that is easy to compare. One that I’ve seen on flight search websites is an “Agony” score that takes into account the number of stops, the price, and the departure time. You could sort by ascending agony and hopefully see the best choice that considered all of the variables, rather than just sorting on price.
I do something like this in my iOS app, Habits. For each habit, I look at your entire history with the habit. I weight recent adherence more than the past and try to come up with a score normalized between 0-100. My intent is that you can use that to compare how well you are doing on different habits.
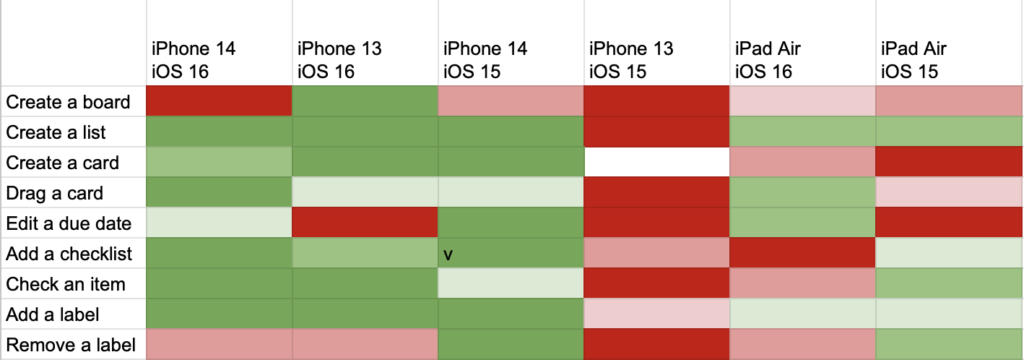
A third way is to map attributes to elements of a chart. One attribute could be the x-axis and another could be the y-axis. You could map one attribute to the size of a dot and another to color along a gradient. If your x and y are categories rather than a continuous value, you might end up with a heatmap. This heatmap compares the amount of testing done on different iPhones and iOS versions.
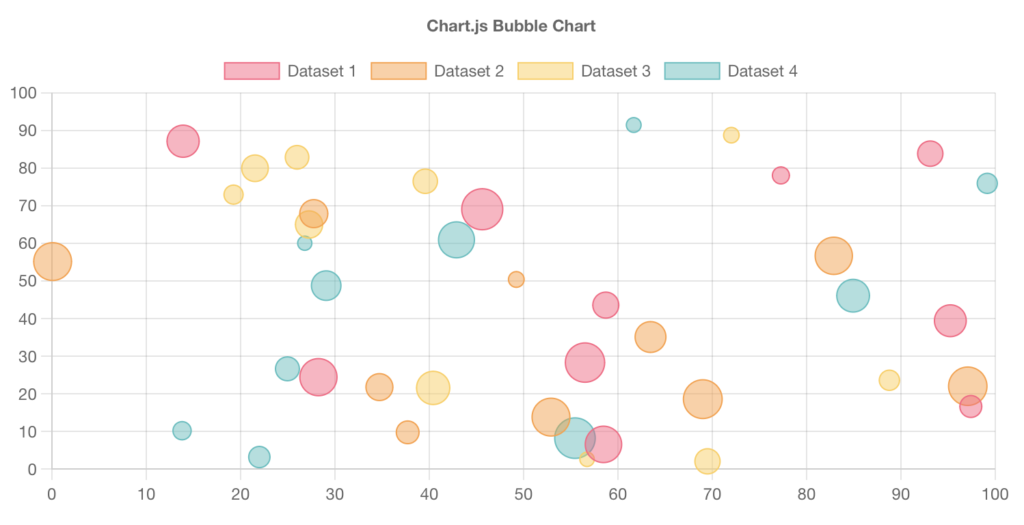
For continuous axes, you might end up with a chart like this one you can generate with chartjs:
In that last chart, it matters which attribute you map to which chart element. It’s often the case that we filter for just the upper-right quadrant, so the x and y would override color and size. You might want to rotate through different choices of the mapping.
Lastly, you could generate radar charts for each thing. Putting the attributes along a multi-dimensional graph like this one:
This works well when you want to combine things to form a balanced whole. By overlaying two radar graphs, you can see if the combination is complementary.
But, you could also get a sense of an ordering. You could calculate the covered area, which is function of the attributes. You could size the spokes and normalize the data on them to express a priority and to dampen the effect of outliers.
I’m thinking a lot about multidimensional comparisons as I consider ways to prioritize projects. I’ll be writing more about this soon.
On my first job, there was a vestigial TODO that always bothered me. It said
/* TODO: PSJB, Is this right? -AW */
I eventually figured out that “PSJB” were the initials of our CEO (who wrote a lot code for the early versions). I knew who AW was, but he left before I started, so I couldn’t ask him what this meant. I wanted to just delete it, but I could never figure out if the code it referred to was right. I left the company before figuring it out—the comment might still be there.
This was a bad way to use TODO.
To avoid this problem for others, for my last PR at Atlassian, I searched for every TODO that I left in the code, which was possible because we were forced to sign them. I resolved each one in some way and then removed it. Saying “toodle-oo” by removing “TODO: Lou” from our code made me smile.
None of these TODOs were there for good reason.
Since I’m 100% in charge of my code style guide these days, I don’t allow TODOs to be merged (it won’t pass linting). But, I do use TODO in the code while I am building a PR if it’s convenient—I’ll be forced to remove it before merge.
The only other TODO I’m ok with is ones that are going to be resolved very soon (within the grace period)—hopefully in a stacked PR.
We use cookies for some of the features of this website. You must accept cookies to continue to use this website.