I keep track of my GitHub open source contributions on this site’s GitHub page, but only back to 2013. According to GitHub, I opened my account in late 2010 to open a couple of issues on Yammer.net, which I was using to build an internal tool for Atalasoft that needed access to our Yammer data (Yammer was a precursor to Slack).
My first GitHub source contribution was to YUICompressor (a JavaScript compression tool) to output a Munge Map to aid debugging. I PR’d it in 2011. I needed this to help debug Atalasoft’s JS code in production.
But, that’s just GitHub. I’ve been posting code in other places before that. Here’s a multithreaded prime number sieve in clojure from 2008. Here’s a port of Apple’s CPPUnit to run on Windows from 2006. I found evidence that I published a JavaScript Code39 Bar Code Generator on my Atalasoft blog in 2008, which also has a Code39 web app based on it (which hosts the JS code). I have a lot of code snippets on StackOverflow, but only after 2008. My first post with code was in 2003 (comparing jUnit and NUnit).
I had a distinct memory of emailing an open source dev with a multi-threaded race condition fix for a C++ data structure that we used at Spheresoft. Looking at a list of our external libraries jarred my memory that it was WFC by Samuel R. Blackburn. I also found the WFC release notes in the Wayback Machine that mention my fix. He migrated WFC to GitHub much later, but I found a comment mentioning my fix. The actual diff predates the migration, but it’s the double-checked locking directly below the comment:
// 1999-12-08
// Many many thanks go to Lou Franco (lfranco@spheresoft.com)
// for finding an bug here. In rare but recreatable situations,
// m_AddIndex could be in an invalid state.So, that’s 1999. Ironically, my oldest verified contribution is actually on GitHub, but predates its release by about eight years. Where’s my green square?
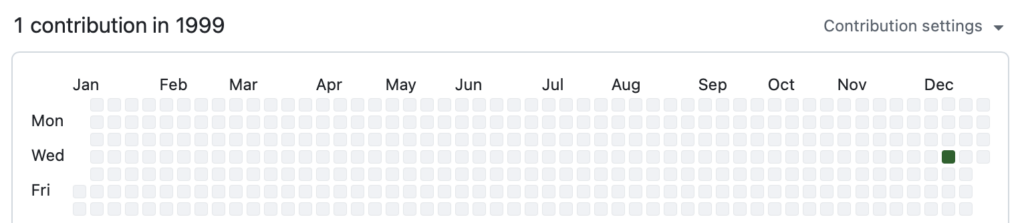
Before that, I have to go by memory because I can’t find the originals.
One thing that came to mind was back in college. I co-developed code for our computer center to draw plots on a Unix PC terminal (saving paper). Using that code, we also built a Unix PC driver for GNU Plot and sent it to them. I am pretty sure this was hosted on MIT’s Athena.
That would be in 1991 or so. I did some simple searches and didn’t find it, but supposedly there are FTP archives from that era, so I might try looking later.